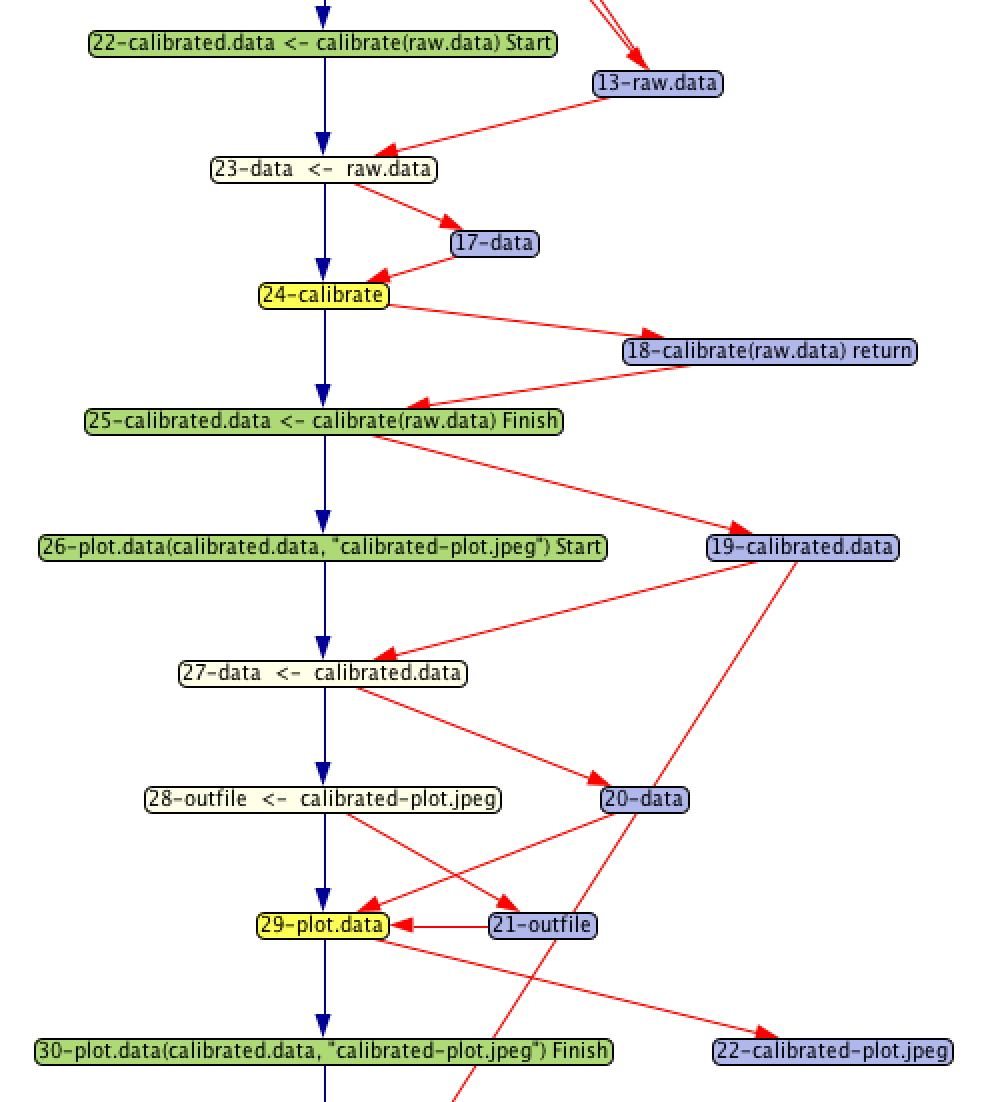
The data provenance that we collect is stored in a graph. The nodes of the graph represent either data or processing steps. Red edges connect the data to the steps that use it as input or produce it as output. Blue edges connect processing steps directly to show control flow relationships.
While not shown in this visualization, the graph captures additional information related to the scientific computation. Data nodes capture the scientific data, including intermediate results produced during computation. Nodes that represent processing steps capture the R source code that the step represents.
The provenance graph snippet shown to the right was generated from running a simple R script demonstrating some basic steps in processing sensor data for general use. Focusing first on the yellow nodes, we see 2 steps:
- Calibrate
- Plot data
Each yellow node represents the execution of a function.
The purple nodes represent data values that are being manipulated by the script. A processing node with an arrow pointing to a data node indicates that the data were output from the processing step. For example, the calibrate step returns the result of doing the calibration.